Wikibookgen - PoC
Wikibookgen
Origin of the issue
I don’t know about you, but I’m the kind of person to open Wikipedia to read an article, opening in other tab all links to cited articles, et winding up 3h later with 50 open tab, reading the biography of Claude Joseph Vernet or the article about the Crystal Palace without any idea on how I got there.
J’ai plusieurs fois ressenti de la frustration à aborder un sujet et de de ne pas comprendre les références citées dans l’article, et j’en suis venu à me demander s’il est possible de créer automatiquement une liste de lecture d’article wikipédia qui serait:
- ordonnées avec les notions utilisées dans les autres article de la liste en premier
- regroupé par thème sémantique
- à partir d’un article de départ
C’est à dire: un livre. Tout simplement un livre, avec des chapitres, et une progression linéaire du savoir.
Bref, est-il possible de générer la table des matières d’un livre sur un sujet donné grâce à Wikipedia ?
Le PoC
La première question à se poser: Y a-t-il effectivement une logique sémantique dans les références Wikipedia ?
J’ai foncé tête baissé sur un PoC en Go. Pour ça j’avais besoin de:
- Récupérer l’intégralité Wikipedia dans une DB avec l’ensemble des relations entre les articles
- Charger un graphe connexe contenant l’article “Source”
- Créer une table des matières à partir de ce graphe
- Créer un
.pdfou un.epubà partir de la table des matières - Profit
Récupérer l’intégralité de Wikipédia
Évidemment, je n’allais pas crawl wikipedia.org, ce serait contraire à l’étiquette de générer du traffic qui ne serve pas à la consultation par un humain. Bien sûr, Wikimedia propose des miroirs de téléchargement des dumps du contenu de Wikipedia. La documentation est ici.
J’ai donc créé un outils wikipedia-to-cockroachdb qui va automatiquement télécharger un à un les dumps de Wikipedia, les ouvrir, et importer les articles dans une instance CockroachDB, tout en parsant les références entre articles pour créer les arêtes du graphe de Wikipedia.
On ne peut pas directement créer un json avec les références d’un article parce que dans le contenu de l’article, on n’a que les arêtes qui PARTENT de l’article, pas les arêtes qui arrivent.
Ce qui nous donne ça:
CREATE TABLE IF NOT EXISTS page (
page_id INT PRIMARY KEY,
title TEXT,
lower_title TEXT
);
/*
** Create index to search page by title, cockroachdb doesn't handle computed index
*/
CREATE INDEX IF NOT EXISTS page_title ON page (lower_title);
/*
** page_content contains plain article content
*/
CREATE TABLE IF NOT EXISTS page_content (
page_id INT PRIMARY KEY REFERENCES page (page_id) ON DELETE CASCADE,
content TEXT
);
/* set number of replicas to 1 (keeping only 1 copy) instead of default 3 for page_content
** keep storage used low, since page_content is a heavy table but not necessary for extensive
** data query
**
** set GC to 1 hour instead of 25 to reclaim storage space faster
**/
ALTER TABLE page_content CONFIGURE ZONE USING num_replicas = 1, gc.ttlseconds = 3600;
/* article_reference contains references to other articles
*/
CREATE TABLE IF NOT EXISTS article_reference (page_id INT, refered_page INT, occurrence INT, reference_index INT, PRIMARY KEY (page_id, refered_page));
/* incoming_reference index allows querying incoming reference for a given article
*/
CREATE INDEX IF NOT EXISTS incoming_reference ON article_reference (refered_page);
/* page_nature table contains page content nature (place, person, ...) and infox box template if present
*/
CREATE TABLE IF NOT EXISTS page_nature (page_id INT PRIMARY KEY, nature INT, infobox TEXT);
Une fois importé la version anglaise de Wikipedia, on se retrouve avec 18172414 pages et 183301241 références interne. On a donc un graphe G = (S,A) d’ordre 18.10^6 avec 10^9 arêtes.
Pour les devops, voici ce que représente en terme d’espace les DBs Wikipedia:
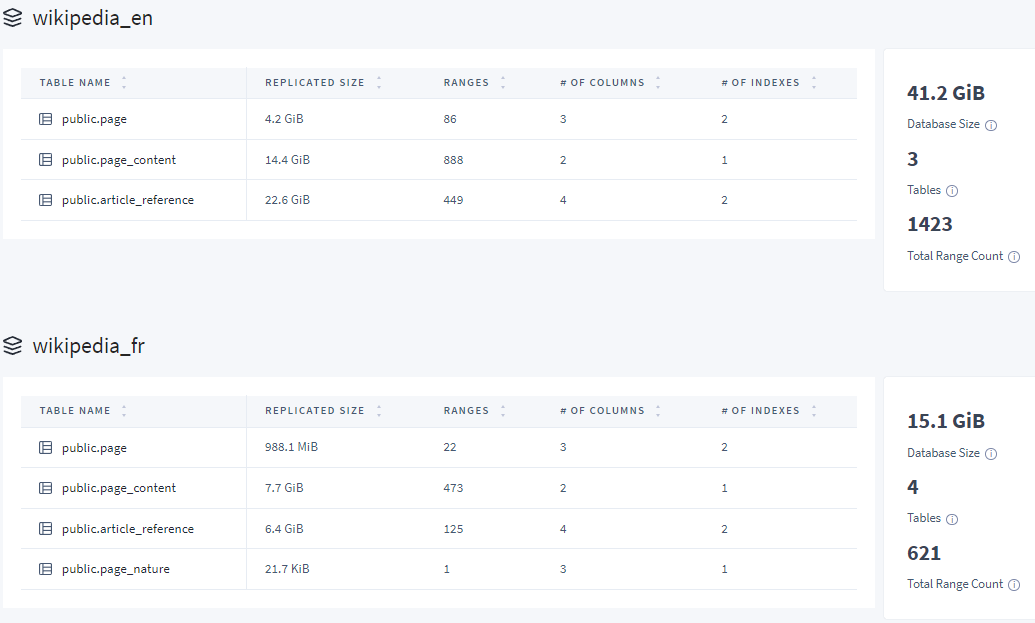
Il faut un peu prévoir le coup quoi.
Charger un graphe connexe contenant l’article Source
Aka, la phase de “Classification”
Je voulais charger en mémoire le graphe connexe le plus grand possible. On peut charger les sommets à partir de la Source de proche en proche, la vraie question ici c’est de savoir quand s’arrêter. Je voulais que la distance à l’article source soit homogène, pour ne pas biaiser le clustering. Pour le PoC, Wikibookgen charge donc de proche en proche jusqu’à une distance de 3. On a donc un graphe formé de chaînes de taille 3 avec la Source en extrémité, et toutes les relations entre les autres sommets.
On voudrait aussi éviter de load certains type d’article, par exemple les biographies, ou les endroits.
Trouver des sous graphes hautement connectés dans G
Aka, la phase de “Clustering”
Maintenant qu’on a un graphe qui contient uniquement des sommets plus ou moins lié à la Source, je voulais créer des “chapitres” de mon livre.
J’ai commencé par vouloir utilisé la méthode de Louvain, mais sans succès. Le temps de calcul était beaucoup trop long.
J’ai alors ajouté une contrainte de temps à mes algorithmes de clustering, avec en gros:
- 1 minute pour un “overview”, c’est à dire moins de 50 pages sans chapitre
- 5 minutes pour un “tour”, c’est à dire moins de 1000 pages avec chapitre
- 10 minutes pour une “encyclopédie”, c’est à dire moins de 10000 pages avec plusieurs volumes avec chapitre
L’algorithme du PoC:
- Forme des graphes hautement connecté avec la Source et une référence directe
- Ensuite divise le temps imparti par le nombre de sous graphe
- Pour chaque sous graphe, ajoute si possible un sommet pour former un sous graphe hautement connecté d’ordre
n+1
Linéariser l’ensemble des sous graphes en table des matières
Aka, la phase d’Ordering.
On a maintenant un ensemble de sous graphe hautement connecté qui contiennent la Source. Il faut maintenant les mettre dans l’ordre pour pouvoir les lire. Il y a deux tris à faire:
- L’ordre des sous graphe (aka Chapitre)
- L"ordre des articles dans les chapitres
L’ordre devrait être “logique”, c’est à dire qu’on veut que les notions nécessaire à la compréhension de la suite soit avant. On veut que les notions les plus “simple” soit au début. Le problème c’est que ce sont des graphes hautement connecté, donc avec des cycles dans tous les sens, par où on commence ?
Dans le PoC, je fais un simple tri à bulle qui classe par nombre de référence ascendant.
Générer un .pdf ou .epub à partir de la table des matières
Maintenant qu’on a une table des matières, on peut générer le format final avec le contenu de chaque article. On a deux problèmes:
- Transformer le format
MediaWikien un format qui puisse être compris par un outils de création de pdf et d’epub, sans les liens internes et externes - Récupérer tout les fichiers externe sur upload.wikimedia.org pour les intégrer dans le livre
C’est ce que fait le package Editor avec l’aide de Pandoc. Le PoC fait du best effort, donc en cas d’erreurs, le chapitre entier est évincé du pdf. Il y a actuellement plein de trous.
Résultat du PoC
Le PoC de Wikibookgen est donc composé d’une API en Go et d’un site en AngularJS. Mes talents de dev front étant ce qu’ils sont, l’UX est dégueulasse et le code ne compile plus, il y a donc seulement une vieille version de l’UI qui tourne sur wikibookgen.org
Exemple avec la source “Greenhouse”
Tout le monde a une vague idée de ce qu’est une serre, on peut donc tous juger de la pertinence de Wikibookgen pour Greenhouse. Voici les 10 premiers chapitres (sur 49):
- Chapter 1: Pollination
- Chapter 2: Humidity
- Chapter 3: Soil
- Chapter 4: Europe
- Chapter 5: Biological pest control
- Chapter 6: Irvington, New York
- Chapter 7: Renewable energy
- Chapter 8: Amsterdam
- Chapter 9: Missouri Botanical Garden
- Chapter 10: Polytunnel
Vous pouvez voir la table des matières complète ici.
Plutôt pas mal non ? Ça parait logique de commencer un livre sur les serres par parler de polénisation, d’humidité, de qualité de sol, puis de donner plusieurs exemple célèbre de serre historique.
Regardons ce que contient le premier chapitre:
- Nectar
- Pollinator
- Pollination management
- Bee
- Greenhouse
- Pollination
- Pollination syndrome
- Pollen
- Buzz pollination
- Bumblebee
- Insect
- Entomophily
Encore un fois, on voit la logique des articles sélectionné pour faire partie de ce chapitre.
Vous pouvez télécharger le pdf de “Tour of Greenhouse” ici
Exemple avec la source “Intégrale de Lebesgue”
Exemple plus spécialisé, et en français. Voici la liste des 10 premiers chapitre (en entier ici):
- Chapitre 1: Espace Lp
- Chapitre 2: Intégration (mathématiques)
- Chapitre 3: Andreï Kolmogorov
- Chapitre 4: Base (algèbre linéaire)
- Chapitre 5: Théorie de la mesure
- Chapitre 6: Espace L1
- Chapitre 7: Absolue continuité
- Chapitre 8: Lviv
- Chapitre 9: Algèbre
- Chapitre 10: Série (mathématiques)
Encore une fois, “ça a l’air” pas mal. Le premier chapitre définit des notions essentielles de l’intégrale de Lebesgue:
- Mathématiques
- Nombre réel
- Analyse fonctionnelle (mathématiques)
- Espace vectoriel
- Nombre complexe
- Mesure de Lebesgue
- Norme (mathématiques)
- Tribu borélienne
- Intégrale de Riemann
- Intégrale de Lebesgue
- Ensemble négligeable
- Produit de convolution
- Semi-norme
- Espace préhilbertien
- Espace Lp
- Série de Fourier
J’ai pris cet exemple par ce que je peux le comparer à l’UE “Intégrale de Lebesgue” de la Sorbonne, et les notions abordés sont vraiment similaire.
La suite ?
Bref, on peut sentir que ça marche “pas mal”, on peut effectivement trouver une logique dans les tables des matières générés par Wikibookgen.
Maintenant, pour que ce soit utile, il faudrait:
- Une UI utilisable, c’est peut-être l’occasion pour moi de tester le language Dart, et produire aussi une application mobile.
- Une façon de mesurer objectivement ce “pas mal”, avec un ou plusieurs métrique calculable.
- Une meilleure édition des pdf et epub, qui soit plus propre et utilisable.
- Une feature d’édition par les humains des tables des matières générées par Wikibookgen, pour enlever les articles hors sujet. Cette feature permettrait d’utiliser Wikibookgen comme base d’édition de livre sans partir de zéro, et me permettrait en plus de comparer les versions générées et les versions éditée par un humain.
Bref, j’adore ce projet et je sens qu’il a le potentiel d’être utile, donc il est temps de s’y remettre.
Je vous invite à essayer par vous même sur https://wikibookgen.org/wikibook/order (uniquement en anglais, la version qui permet de choisir la langue ne compile plus…)